 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪些是能够使用map-reduce框架并能将训练集划分到多台机器上进行并行训练的()。
A.逻辑斯特回归(LR),以及随机梯度下降(SGD)
B.线性回归及批量梯度下降(BGD)
C.神经网络及批量梯度下降(BGD)
D.针对单条样本进行训练的在线学习
 答案
答案
ABCD
 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.逻辑斯特回归(LR),以及随机梯度下降(SGD)
B.线性回归及批量梯度下降(BGD)
C.神经网络及批量梯度下降(BGD)
D.针对单条样本进行训练的在线学习
答案
ABCD
如果结果不匹配,请 联系老师 获取答案
 更多“假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪…”相关的问题
更多“假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪…”相关的问题
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程

变量sleep是每周晚上睡眠的总分钟数, ton work是每周花在工作上的总分钟数, educ和age则以年为单位,而male是一个性别虚拟变量。
(i)所有其他因素不变,有没有男性比女性睡眠更多的证据?这个证据有多强?
(ii)工作与睡眠之问有统计显著的取舍关系吗?所估计的取舍关系是什么样的?
(iii)为了检验年龄在其他因素不变的情况下对睡眠没有影响这个虚拟假设,你还需要另外做什么回归?

利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭都(随机地)介绍了正常苹果和环保苹果的一组价格,并询问他们愿意购买每种苹果的磅数。
(i)对于样本中的660个家庭,有多少家庭报告称在预定价格上不愿意购买环保苹果?
(ii)变量ecolbs看上去在严格正值上具有连续分布吗?你的回答对ecolbs托宾模型的适当性有何含义?
(iii)以ecoprc、regprc、famic和hhsize作为解释变量,估计一个托宾模型。哪些变量在1%的水平上显著。
(iv)faminc和hhsize联合显著吗?
(v)第(iii)部分中价格变量系数的符号与你的预期一致吗?请解释。
(vi)令β1和β2为ecoprc和regprc的系数,相对一个双侧备择假设,检验假设H0:-β1=β2。报告检验的p值。(如果你的回归软件不能很容易地计算这种检验,你可能还要参考教材4.4节
(vii)对样本中的所有观测求E(ecolbslx)的估计值[见方程(17.25)],称之为ecolbsi。最大和最小拟合值是多少?
(viii)计算ecolbs,和ecolbsi之相关系数的平方。
(ix)现在,利用第(iii)部分中同样的解释变量,估计ecolbs的一个线性模型。为什么OLS估计值比托宾估计值小那么多?从拟合优度来看,托宾模型比线性模型更好吗?
(x)评价如下命题:“由于托宾模型的R,如此之小,所以估计的价格效应可能是不一致的。”
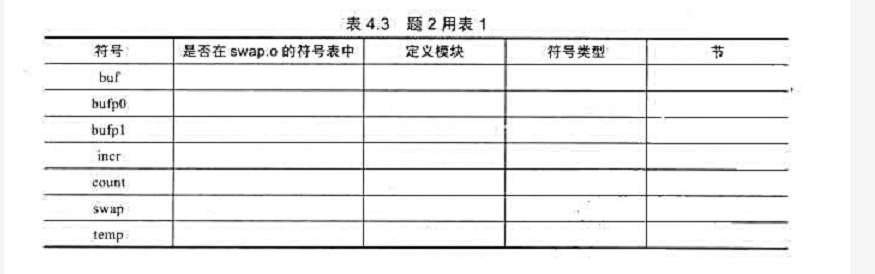
如下模型使得受教育回报还取决于父母双方受教育程度的总和pareduc:

如果某人父母总的教育年限为32年,那么他的教育回报比父母教育年限为24的人高百分之多少?这个差异在统计上显著吗?
(iii)如果在方程中将pareduc作为一个独立变量引入,则得到
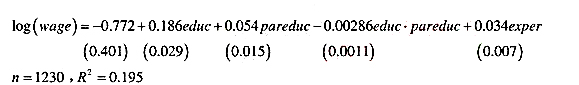
现在教育回报如何依赖于父母的受教育水平?找到双侧p值来检验原假设:教育回报取决于父母的受教育水平。你能得到什么结论?
北方高科技有限公司成功地生产和销售两种打印机,假设该公司两种产品的财务和成本数据如下: 公司管理会计师划分了下列作业、间接成本集合及成本动因:
公司管理会计师划分了下列作业、间接成本集合及成本动因: 两种产品的实际作业量如下:
两种产品的实际作业量如下: 要求: (1)采用传统(产量基础)成本计算制度,以直接人工工时为分配标准,确定两种产品的单位产品成本及单位盈利能力。 (2)采用作业基础成本计算制度,确定两种产品的单位产品成本及单位盈利能力。
要求: (1)采用传统(产量基础)成本计算制度,以直接人工工时为分配标准,确定两种产品的单位产品成本及单位盈利能力。 (2)采用作业基础成本计算制度,确定两种产品的单位产品成本及单位盈利能力。
假设你有兴趣检测NAT后面的主机数量。你观察到在每个IP分组上IP层顺序地标出一个标识号。由一台主机生成的第一个IP分组的标识号是一个随机数,后继IP分组的标识号是顺序分配的。假设由NAT后面主机产生的所有IP分组都发往外部。 a.基于这个观察,假定你能够俘获由NAT向外部发送的所有分组,你能概要给出一种简单的技术来检测NAT后面不同主机的数量吗?评估你的答案。 b.如果标识号不是顺序分配而是随机分配的,这种技术还能正常工作吗?评估你的答案。
本题需要使用ELEM 94-95中的数据, 也可参见计算机习题C 4.10。
(i) 利用所有数据, 将lavg sal对bs, lenrol, Istaff和lunch进行回归。报告bs的系数及其常用标准误和异方差-稳健标准误。你对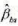 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?
(ii)现在去掉四个bs>0.5的观测,即平均福利(假设)占平均薪水50%以上的观测。bs的系数又是多少?利用异方差-稳健标准误来判断,它在统计上显著吗?
(iii)验证bs>0.5的四个观测分别为68、1127、1508和1670。为它们各定义一个虚拟变量。(你可以称它们为d68、d1127、d 1508和d 1670.) 把它们添加到第(i) 部分的回归中, 验证其他变量的OLS系数及其标准
误与第(ii)部分中的结果相同。在5%的显著性水平上,这四个虚拟变量中哪个变量的t统计量在统计上显著不等于0?
(iv)在这个数据集中,验证第(iii)部分回归中具有最大学生化残差(该虚拟变量的t统计量最大)的数据点对OLS估计值具有很大的影响。(即利用除去具有最大学生化残差的数据点之外的所有观测进行OLS回归。)依次去掉bs>0.5的每个观测都具有重要影响吗?
(v) 即便在大样本中, 就OLS对单个观测的敏感性而言, 你有何结论?
(vi) 在第(iji) 部分, 验证LAD估计量对包含这些观测不是很敏感。

















