 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用HSEINV.RAW中的数据。(i)检验log(in vpc)是否有单位根, 模型中含有一个线性时间趋势和
本题利用HSEINV.RAW中的数据。(i)检验log(in vpc)是否有单位根, 模型中含有一个线性时间趋势和
本题利用HSEINV.RAW中的数据。
(i)检验log(in vpc)是否有单位根, 模型中含有一个线性时间趋势和 log(in ypct)的两阶滞后, 显著性水平为5%。
(ii)用第(i)部分中的方法检验log(price)中的单位根。
(iii)给定第(i)部分和第(ii)部分中的结果,那么检验log(iv pc)和log(price)之间的协整还有意义吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“本题利用HSEINV.RAW中的数据。(i)检验log(in…”相关的问题
更多“本题利用HSEINV.RAW中的数据。(i)检验log(in…”相关的问题
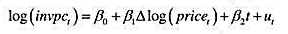

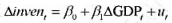 中求出OLS残差,并用
中求出OLS残差,并用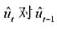 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?

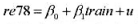 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?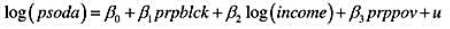
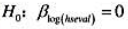 的双侧p值。
的双侧p值。















