 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
已知模型的普通最小二乘法估计残差的一阶自相关系数为0,则DW统计量的近似值为()。
A.0
B.1
C.2
D.4
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.0
B.1
C.2
D.4
如果结果不匹配,请 联系老师 获取答案
 更多“已知模型的普通最小二乘法估计残差的一阶自相关系数为0,则DW…”相关的问题
更多“已知模型的普通最小二乘法估计残差的一阶自相关系数为0,则DW…”相关的问题
利用WAGEPAN中数据。
(i)利用混合最小二乘法(pooledOLS)估计一个log(ag为被解释变量的方程。以educ,black,exper,married,union以及一系列时间虚拟变量(以1980年为基年)为可解释变量,解释及讨论变量married和union的系数。
(ii)解释为什么通常(i)中标准误总是偏小。算出关于married和union两个变量对自相关和异方差一稳健的标准误。
(iii)现在对变量lwage,exper,married和union进行一阶差分。(不随时间改变的变量educ,black和hisp被排除在这个估计之外,exper也是,因为它总是随着年份增加。)注意排除首年即1980年的一阶差分,因为不存在更早的年份。
(iv)就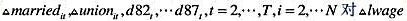 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
(v)对比婚姻状况和工会保费的估计水平及其一阶差分估计,并作相应评论。
利用TRAFFIC2.RAW中的数据。
(i)计算变量prefat的一阶自相关系数。你认为prefat包含单位根吗?失业率也一样吗?
(i)估计一个将prcfat的一阶差分Aprcfat与第10章的计算机练习C11第(vi)部分中同样变量相联系的多元回归模型,只是你还应该对失业率进行一阶差分。于是,模型中包含一个线性时间趋势、月度虚拟变量、周末变量和两个政策变量;不要将这些变量进行差分。你发现了什么有意思的结论吗?
(iii)评论如下命题:“在进行多元回归之前,我们总应该将怀疑具有单位根的时间序列进行一阶差分,因为这样做是一种安全策略,而且应该得到与使用水平值类似的结论。”[在回答这个问题时,最好先做(如果你还没有做过的话)第10章的计算机练习C11第(vi)部分中的回归。]
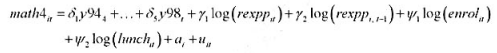
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差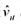 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用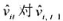 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?


其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差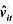 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用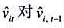 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为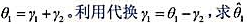 的标准误。
的标准误。
在例11.6中,我们估计了一个一阶差分形式的有限分布滞后模型:
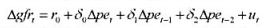
利用FERTIL 3.RAW中的数据来检验误差中是否存在AR(1) 序列相关。
利用CHARITY.RAW中的数据回答如下问题
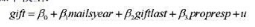
(i)用普通最小二乘法估计如下模型:
按照通常的方式报告估计方程,包括样本容量和R²。其R²与不使用giftlast和propresp的简单回归所得到的R²相比如何?
(ii)解释mailsyear的系数,它比对应的简单回归系数更大还是更小?
(iii)解释propresp的系数,千万要注意propresp的度量单位。
(iv)现在,在这个方程中增加变量avggif。这将对mailsyear的估计效应造成什么样的影响?
(v)在第(iv)部分的方程中,giftlast的系数有何变化?你认为这是怎么回事?
使用CRIME4.RAW。
(i)在数据集中增加每个工资变量的对数,然后用一阶差分估计模型。问这些变量的引入如何影响教材例13.9中那些司法变量的系数?
(ii)第(i)部分中的工资变量全部都有预期的符号吗?它们是联合显著的吗?试解释。

















