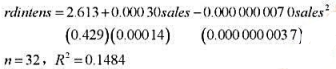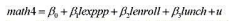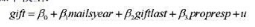题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
使用GPA1.RAW中的数据。 (i)在估计方程(7.6)中增加变量mothcoll和fathcoll,并以通常的形式报告
使用GPA1.RAW中的数据。
(i)在估计方程(7.6)中增加变量mothcoll和fathcoll,并以通常的形式报告结果。拥有PC的估计影响会怎么样?PC还是统计显著的吗?
(ii)检验第(i)部分方程中mothcoll和fathcoll的联合显著性,不要忘记报告p值。
(iii)在第(i)部分的模型中增添hsGPA,并判断是否有必要进行这种扩展。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“使用GPA1.RAW中的数据。 (i)在估计方程(7.6)中…”相关的问题
更多“使用GPA1.RAW中的数据。 (i)在估计方程(7.6)中…”相关的问题