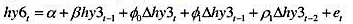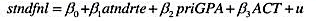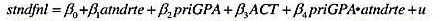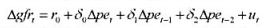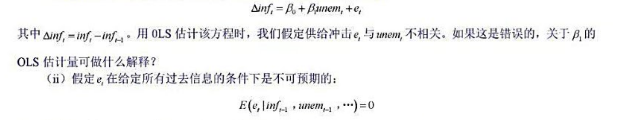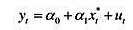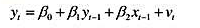题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在教材例10.6中,我们估计了费尔预测美国总统选举结果的一个模型的变型。 (i)对于这个方程中的
在教材例10.6中,我们估计了费尔预测美国总统选举结果的一个模型的变型。
(i)对于这个方程中的误差项序列无关,你有何论据?(提示:总统选举多长时间进行一次?)
(i)在将教材(1023)的OLS残差对滞后残差进行回归时,得到p=-0068和sep)=0.40。你对ut中的序列相关有何结论?
(iii)在检验序列相关时,这个应用中的小样本容量会令你不放心吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“在教材例10.6中,我们估计了费尔预测美国总统选举结果的一个…”相关的问题
更多“在教材例10.6中,我们估计了费尔预测美国总统选举结果的一个…”相关的问题
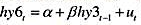 中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程
中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程